데이터가 없어서, 모델보다 데이터부터 만들었습니다
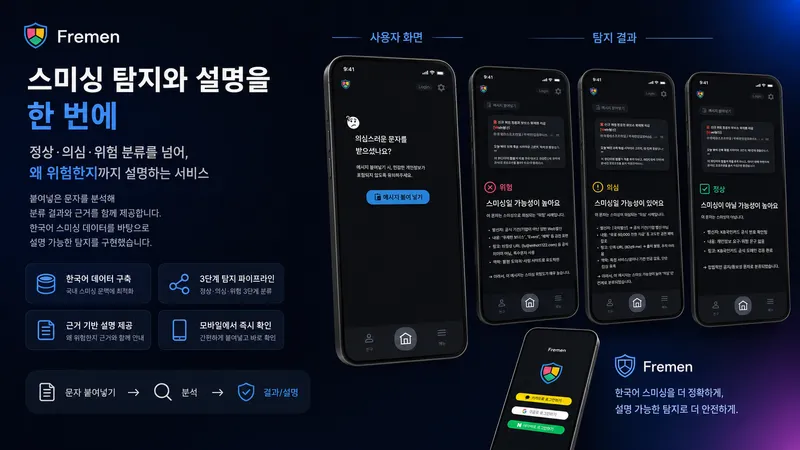
지산학 캡스톤(2025.09–12)에서 팀장으로 AI 파이프라인을 맡은 임현우입니다. 저희가 만든 Fremen은 스미싱 문자를 받았는지 묻고, 붙여넣은 메시지를 정상·의심·위험으로 나눠주는 탐지 서비스입니다.
스팸이냐 아니냐, 둘 중 하나로 잘 가르면 되는 문제 아닐까 — 처음엔 그렇게 가볍게 봤거든요. 그런데 의심 문자를 받은 사람 입장이 되어 보니, 분류 결과 한 줄로는 한참 부족하더라고요. '위험'이라고만 떠 있으면 사용자는 '이게 왜 위험한데?'라는 질문을 그대로 안고 있게 됩니다. 판정을 믿고 문자를 지울지, 무시하고 링크를 누를지는 결국 그 '왜'에서 갈리거든요.
그래서 분류로 끝내지 않고, 근거를 찾아 설명까지 만드는 쪽으로 방향을 잡았습니다. 문제는 그렇게 학습시키려면 양질의 한국어 스미싱 데이터가 있어야 하는데, 그게 공개돼 있지 않았다는 겁니다.
왜 분류만으론 부족했을까요?
스미싱 탐지를 '위험/정상' 이진 분류로만 두면, 모델은 점수를 내놓아도 사람이 행동을 바꿀 근거는 못 줍니다. 같은 단축 URL이라도 어떤 건 합법 광고고 어떤 건 피싱 유도라, '위험' 라벨 하나만으로는 사용자가 판정을 믿기 어렵습니다.
더 근본적인 벽은 데이터였습니다. 영어권 스팸 데이터셋은 많지만, 한국어 스미싱은 발신처 표기·도박/사행성 문구·기관 사칭 패턴이 우리 환경에 고유합니다. 외국어 데이터로 학습한 모델을 그대로 가져다 써서는 '왜 위험한지'를 한국어 맥락으로 설명할 수 없었습니다.
정리하면 풀어야 할 일이 세 겹으로 겹쳐 있었습니다. (1) 학습시킬 한국어 데이터를 직접 확보하고, (2) 정상·의심·위험을 가르는 분류기를 만들고, (3) 그 판정에 붙일 '근거와 설명'까지 한 흐름으로 묶는 것. 저는 이 셋을 하나의 파이프라인으로 잇는 설계를 맡았습니다.
8,404건을 직접 라벨링하며 시작했습니다
모델 아키텍처를 고민하기 전에, 저희는 KISA 스미싱 데이터 8,404건을 직접 수집하고 라벨링하는 일부터 했습니다. 8천 건을 사람이 직접 분류한다는 게 처음엔 막막했는데, 라벨을 붙이다 보니 오히려 도메인이 손에 잡혔습니다. 도박/사행성 문구, 기관 사칭, 추적이 어려운 단축 URL 같은 패턴이 반복적으로 보이기 시작하더라고요.
이렇게 만든 데이터를 8:1:1로 학습·검증·테스트 세트로 나눴습니다. 라벨링 기준을 팀 안에서 합의하는 과정 자체가, 나중에 '근거 설명'을 어떻게 구성할지에 대한 밑그림이 됐습니다.
분류 → 근거 검색 → 설명, 3단으로 풀었습니다
핵심 설계는 '분류 하나로 끝내지 않는다'였습니다. 판정과 그 근거, 사용자가 읽을 설명을 각각 다른 단계가 맡도록 파이프라인을 세 단으로 나눴습니다.
- 1
1단계 — 분류 (KoBERT)
붙여넣은 문자를 한국어 사전학습 모델 KoBERT로 분류합니다. 이미지로 온 문자는 온디바이스 YOLO/OCR로 텍스트를 복원해 같은 흐름에 태웁니다.
- 2
2단계 — 근거 검색 (RAG)
분류 결과를 곧이곧대로 믿게 두지 않고, multilingual-e5 임베딩 기반 RAG로 유사 사례·근거를 검색해 '왜 그렇게 봤는지'의 재료를 모읍니다.
- 3
3단계 — 설명 생성 (LLM)
검색한 근거를 바탕으로 생성형 LLM이 발신처·내용·링크를 항목별로 짚어 사람이 읽을 설명을 만듭니다.
흐름을 코드로 단순화하면 이런 모양입니다. 분류 점수만 돌려주는 게 아니라, 근거를 검색해 설명까지 함께 묶어 내보냅니다.
pythondef detect(message: str) -> Verdict: text = restore_text(message) # YOLO/OCR로 이미지 → 텍스트 복원 score = kobert.classify(text) # 1단계: KoBERT 분류 점수 evidence = retriever.search(text) # 2단계: multilingual-e5 RAG 근거 검색 reason = llm.explain(text, evidence)# 3단계: 근거 기반 설명 생성 return Verdict( level=to_risk_level(score), # 임계값 기반 정상/의심/위험 reason=reason, # 발신처·내용·링크 근거 )

왜 굳이 단계를 늘렸을까요? (트레이드오프)
분류 모델 하나면 응답도 빠르고 구조도 단순합니다. 단계를 RAG·LLM으로 늘리면 파이프라인이 길어지고 그만큼 손이 더 가는 게 사실입니다. 그래서 이 결정에도 분명한 비용이 있었습니다. 한계부터 인정하고 가겠습니다.
| 선택지 | 장점 | 치른 비용 |
|---|---|---|
| 분류 모델만 | 빠르고 단순, 운영 부담 적음 | 판정에 '왜'가 없어 사용자가 신뢰하기 어려움 |
| 분류 + RAG + 생성 LLM | 근거·설명이 붙어 신뢰 가능한 결과 | 파이프라인이 길어지고 단계마다 검증 필요 |
저희는 '사용자가 판정을 믿고 행동을 바꿀 수 있는가'를 가장 중요한 기준으로 봤습니다. 그래서 길어지는 비용을 감수하고 분류 + RAG + 생성 LLM을 결합하는 쪽을 택했습니다. 판정에 '왜'가 붙는 순간, 결과의 성격 자체가 달라지더라고요.
위험뿐 아니라 정상·의심도 같은 방식으로 설명합니다. 출처 불명·추적이 어려운 단축 URL 같은 신호는 '의심' 단계로, 도메인 검증을 통과한 공식 발신은 '정상'으로 — 임계값을 기준으로 세 단계 리스크를 가릅니다.


결과 — 수치로 확인한 것
직접 만든 데이터와 3단 파이프라인으로 테스트 세트에서 다음 성능을 얻었습니다. 수치는 분류 성능에 대한 것이고, 그 위에 근거·설명 단계를 더한 게 이 프로젝트의 핵심입니다.
| 지표 | 값 |
|---|---|
| Weighted F1 | 0.93 |
| Precision | 0.91 |
| Recall | 0.95 |
| 직접 수집·라벨링 | 8,404건 (8:1:1) |
| 리스크 분류 | 정상·의심·위험 3단계 |
Recall이 0.95로 비교적 높게 나온 건 스미싱 탐지의 성격상 의미가 있었습니다. 위험한 문자를 놓치는 쪽이 멀쩡한 문자를 잘못 거르는 쪽보다 사용자에게 더 치명적이라, 놓침을 줄이는 방향이 이 도메인엔 맞았거든요.
배운 것과 남은 과제
가장 크게 남은 건 첫 문장에서 했던 고민의 답이었습니다. 모델 성능은 결국 데이터에서 나온다는 것. 아키텍처를 바꾸기 전에 데이터를 직접 만들고 라벨 기준을 합의하는 일이, 뒤따른 모든 결정을 떠받치는 토대였습니다.
솔직히 남은 과제도 있습니다. RAG·LLM 단계를 더하면서 늘어난 지연과 운영 비용을 어떻게 줄일지, 그리고 새로운 스미싱 유형이 끊임없이 생겨나는 상황에서 8,404건으로 만든 데이터를 어떻게 계속 갱신할지는 캡스톤 기간 안에 다 풀지 못했습니다.
그래서 다음에 비슷한 문제를 만나면 모델보다 데이터부터 의심하고 들어갈 생각입니다. 남은 지연·갱신 과제는 다음에 풀어볼 제 숙제로 들고 가겠습니다.