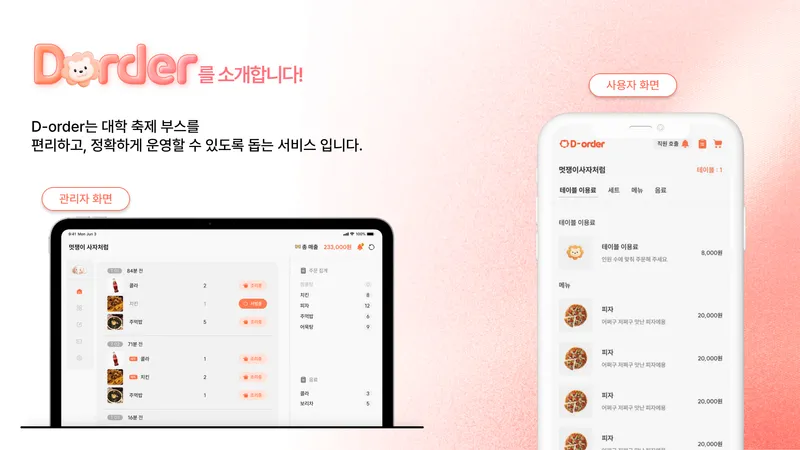
수기로 받던 주문을, 이틀 동안 28만 건 받게 되기까지
안녕하세요. D-Order에서 백엔드 리드와 아키텍트, 현장 운영까지 맡았던 임현우입니다. D-Order는 해마다 2~3만 명이 찾는 동국대학교 축제의 주점을 수기 주문에서 실시간 주문·결제·통계 시스템으로 옮긴 테이블오더 플랫폼이에요.
처음 이 일을 시작한 이유는 사실 거창하지 않았습니다. 주점은 주문을 손으로 받았고, 회장단이 해마다 바뀌다 보니 작년에 뭐가 얼마나 팔렸는지 같은 기록조차 안 남았거든요. 그 현장을 디지털로 옮겨 보자는 게 출발점이었습니다.
그런데 막상 옮기고 보니, 평소에는 트래픽이 거의 없다가 축제 이틀에만 모든 게 한꺼번에 쏟아지는 시스템이 되어 있더라고요. 시즌 누적 28만 건, 하루 5,000건, 피크에는 같은 순간에 500건이 들어옵니다. 이 글은 그 버스트를 견디면서 결제 오류를 0건으로 막으려고, 락 하나로 시작했다가 문제별로 잠금을 나눠 가게 된 과정을 정리한 기록이에요.
같은 메뉴를 두 손님이 동시에 주문하면, 무슨 일이 벌어질까요?
디지털로 옮기는 일 자체는 어렵지 않았어요. 진짜 어려운 건 따로 있었는데요. 축제 현장에서는 절대 어긋나면 안 되는 게 두 가지였습니다. 돈이 오가는 결제, 그리고 한정된 수량의 재고였어요.
한정 수량으로 푼 세트 메뉴를 떠올려 보면 이해가 빠릅니다. 마지막 한 세트가 남았는데 두 테이블이 같은 순간에 주문 버튼을 누른다면요? 두 요청이 모두 "아직 재고 있음"을 읽고 둘 다 통과해 버리면, 시스템상으로는 팔 수 없는 수량이 팔리고 결제까지 끝나 버립니다. 현장에서는 그 자리에서 바로 사고가 돼요.
문제는 이게 한 가지 성격이 아니었다는 거예요. 한 요청 흐름 안에 정합성(재고·결제가 정확해야 함), 동시성(같은 순간 들어오는 요청), 실시간 동기화(손님·운영진·주방이 같은 상태를 봐야 함)가 겹쳐 있었습니다. 트래픽도 평탄하지 않고 버스트로 들어오니, 평소 멀쩡하던 코드가 피크 단 몇 초에 무너질 수 있는 구조였어요.
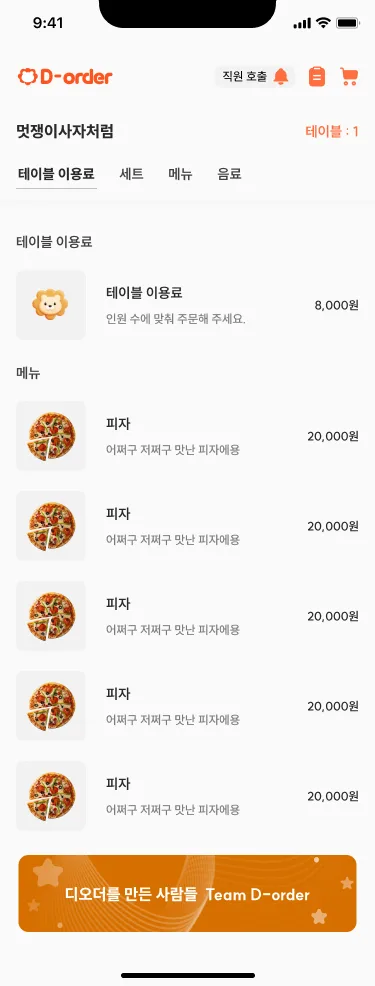
그래서 처음엔 락을 하나로 통일하려 했습니다
동시성 문제를 처음 마주하면 가장 끌리는 선택지가 있습니다. 잠금 하나로 전부 덮는 거예요. 주문 처리 경로 전체를 하나의 락으로 감싸면, 동시에 들어온 요청들이 줄을 서서 한 번에 하나씩 처리되니 재고도, 결제도, 서빙 수락도 어긋날 일이 없어 보였습니다.
코드도 단순해지고요. 한 군데만 잠그면 되니까 처음엔 가장 안전한 길처럼 보였어요.
다시 들여다보니, 제가 풀어야 할 건 사실 한 덩어리가 아니라 성격이 다른 두 문제였습니다. 하나는 "절대 어긋나면 안 되는" 결제·재고였고, 다른 하나는 "먼저 잡은 쪽이 처리하면 되는" 서빙 동시 수락이었어요. 같은 락으로 둘 다 덮으려던 게 애초에 무리였던 거죠.
정합성은 문제별로 — 락을 둘로 나눴습니다
그래서 잠금을 문제 성격에 맞춰 둘로 갈랐습니다. 한 가지 락으로 전부 덮지 않기로 한 거죠.
- 1
결제·재고는 비관적 락으로
정확함이 최우선인 결제와 재고는 select_for_update(비관적 락)로 해당 행을 먼저 잠그고, 예약 수량을 검증한 뒤, 재고를 넘기면 HTTP 409로 거절했습니다. 마지막 한 세트를 두 요청이 동시에 노려도, 행을 먼저 잡은 쪽만 통과하고 나머지는 409로 막힙니다.
- 2
서빙 동시 수락은 분산 락으로
서버 직원 여러 명이 같은 음식을 동시에 수락하려는 상황은 '먼저 잡은 쪽이 처리'면 충분합니다. 여기는 Redis 분산 락(SETNX)으로 분리해, DB 행을 무겁게 잠그지 않고도 한 명만 수락하게 했어요.
핵심은 한 줄로 요약됩니다. 결제 정합성과 서빙 동시성은 성격이 다른 문제라서, 각자에 맞는 도구로 풀어야 한다는 거예요.
python# 결제·재고: 비관적 락으로 행을 먼저 잠그고, 예약 수량을 넘기면 409 with transaction.atomic(): menu = Menu.objects.select_for_update().get(id=menu_id) if menu.reserved + qty > menu.stock: raise Conflict(409) # 한정 수량 초과 → 거절 menu.reserved += qty menu.save()
python# 서빙 동시 수락: Redis 분산 락(SETNX) — 먼저 잡은 한 명만 처리 if redis.set(f"serve:{order_id}", worker_id, nx=True, ex=10): accept_serving(order_id, worker_id) else: # 이미 다른 직원이 수락한 주문
락만 잠그면 끝일까요? — 커밋된 변화만 실시간으로 퍼지게
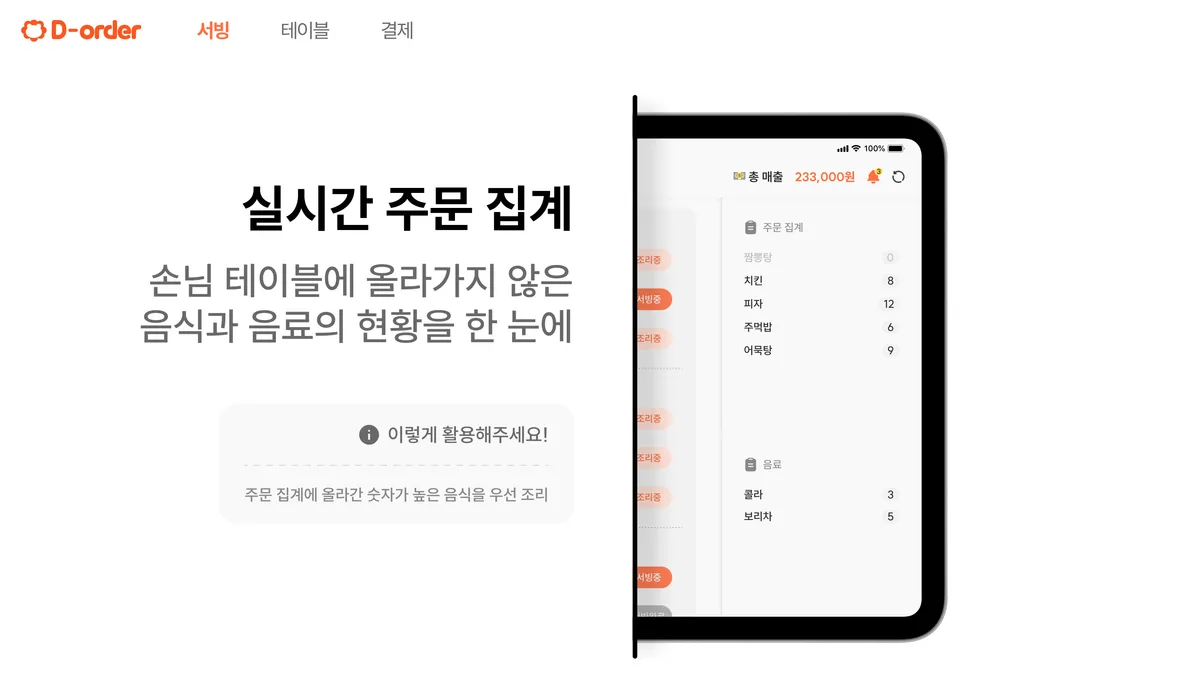
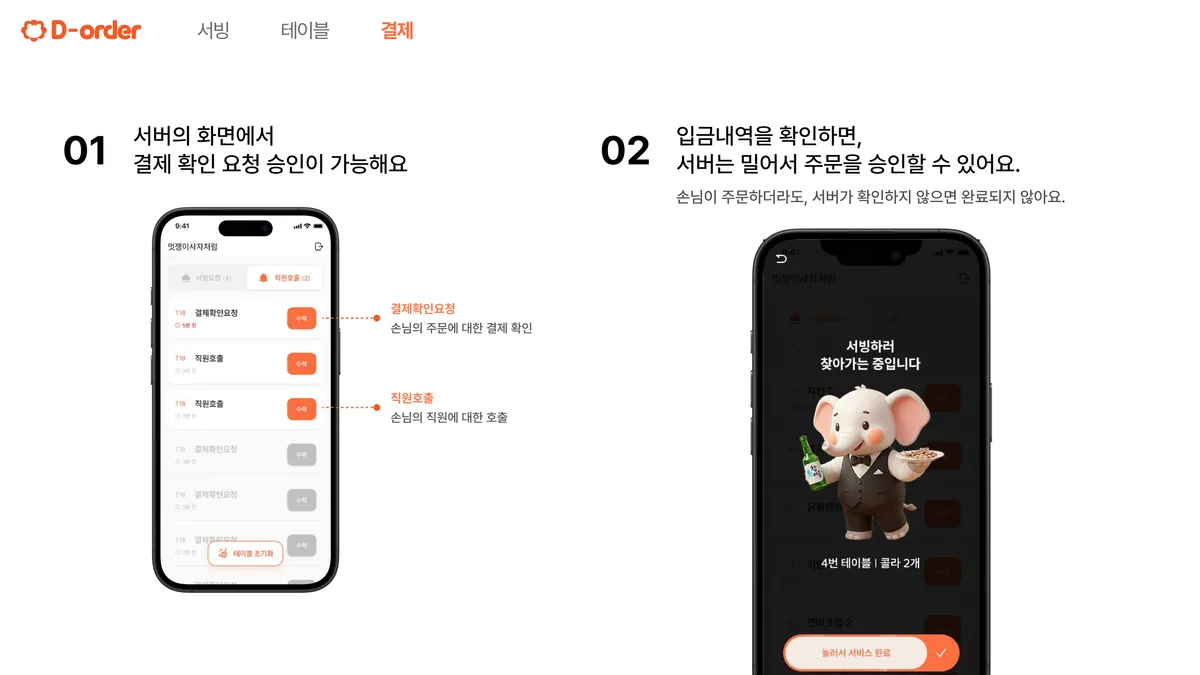
정합성을 지켜도 문제가 하나 남습니다. 손님 화면, 서버 화면, 관리자 태블릿이 같은 주문을 서로 다른 상태로 보면 현장이 헷갈려요. 그래서 상태 변화를 실시간으로 모든 디바이스에 알려야 했습니다.
여기서 함정이 하나 있었는데요. 트랜잭션이 끝나기 전에 "주문 들어왔다"고 먼저 알려 버리면, 정작 DB 커밋이 실패했을 때 화면에는 있는데 데이터에는 없는 유령 주문이 생깁니다. 그래서 알림은 반드시 커밋이 끝난 시점에만 보내도록 transaction.on_commit에 묶었어요.
python# 커밋이 실제로 끝난 뒤에만 브로드캐스트 → 유령 주문 방지 def place_order(...): with transaction.atomic(): order = create_order(...) transaction.on_commit( lambda: broadcast_ws(order) # WebSocket으로 모든 디바이스에 전파 )
이렇게 커밋된 변화만 WebSocket으로 퍼지게 하니, 손님·운영진·주방 디바이스가 같은 상태를 보게 됐습니다. 관리자 태블릿에서는 아직 테이블에 올라가지 않은 음식·음료를 실시간으로 집계해, 많이 나간 메뉴부터 먼저 조리할 수 있었고요.
현장에서 터지기 전에, 먼저 한계를 재 봤습니다
락을 나누고 브로드캐스트를 커밋에 묶었어도, 정작 축제 당일 피크를 못 견디면 소용이 없습니다. 그래서 한계를 현장이 아니라 사무실에서 미리 재 두기로 했어요.
- 1
워커 튜닝
Gunicorn 워커 수를 조정해 동시 요청을 받아 낼 처리 폭을 확보했습니다.
- 2
부하 테스트
k6로 400VU 부하 테스트를 돌려, 피크 동시 500건에 가까운 부하에서 어디가 먼저 무너지는지 미리 확인했습니다.
- 3
무중단 배포
축제 도중에도 고쳐 올려야 할 일이 생기므로, Docker Blue-Green으로 무중단 배포를 구성했습니다.
이 단계 덕분에, 당일 트래픽이 몰려도 "여기서 막힐 수 있다"는 지점을 이미 알고 들어갈 수 있었습니다.
트레이드오프를 다 안고 가는 게 맞을까요?
이 선택들에도 치를 비용이 있었습니다. 한계를 먼저 인정하고 가는 게 맞다고 봐서, 의사결정과 그 대가를 표로 정리해 봤습니다.
| 고민한 지점 | 선택 | 대신 감수한 것 |
|---|---|---|
| 락을 하나로 통일할까? | 문제별로 비관적 락 / 분산 락 분리 | 코드 경로가 둘로 늘지만, 성격이 다른 문제를 각자 맞는 도구로 풉니다. |
| Django에서 멈출까, Spring으로 갈까? | v3에서 신규 기능만 Spring 시범 도입 | 두 스택을 잠시 함께 운영하는 부담이 있지만, 점진 마이그레이션으로 v4 전면 전환을 안전하게 노립니다. |
두 번째 줄이 v3에서 새로 시작한 시도입니다. 한 번에 스택을 갈아엎는 대신, 신규 기능만 Spring으로 시범 도입해 기존 Django와 잠시 함께 운영하는 strangler-fig 방식으로 갔어요. 두 스택을 동시에 굴리는 부담은 있지만, v4 전면 전환을 점진적이고 되돌릴 수 있게 가져가려는 선택이었습니다.
결과 — 0건은 운이 아니라 구조였습니다
결과부터 말씀드리면, 시즌 누적 28만 건을 처리하는 동안 결제 오류는 0건이었습니다.
| 지표 | 수치 |
|---|---|
| 시즌 누적 주문 | 28만+ 건 |
| 하루 처리량 | 5,000건 |
| 피크 동시 처리 | 동시 500건 |
| 결제 오류 | 0건 |
숫자를 자랑하려는 건 아닙니다. 다만 락을 하나로 통일했더라면 피크에서 어딘가 막혔을 테고, 브로드캐스트를 커밋에 묶지 않았더라면 유령 주문으로 정합성이 흔들렸을 거예요. 결제 오류 0건은 운이 좋아서가 아니라, 문제를 성격대로 나눠 막은 구조에서 나온 결과에 가깝다고 봅니다.
저는 v1(2025 봄)에 백엔드를 처음 만들었고, v2에서 팀장, v3에서 리드·아키텍트·현장 운영을 맡았습니다(14인 팀). 축제 현장에서 트래픽을 직접 맞으며 장애를 판단했고, v3부터는 운영 자동화를 넘어 매출·메뉴 통계까지 돌려주는 단계로 끌어올렸습니다.
배운 것, 그리고 아직 남은 숙제
현장에서 트래픽을 직접 맞아 보고 나서 생각이 하나 바뀌었습니다. 장애는 운이 나빠서가 아니라, 구조가 그걸 허용해서 난다는 거예요. 한 번 터질 뻔한 지점은 다시는 안 터질 구조로 바꿔 두는 습관이, 이 현장에서 생겼습니다.
동시에, 락을 나눈 선택이 모든 상황에서 정답이라고 단정하지는 않습니다. 코드 경로가 둘로 늘어난 만큼 유지보수할 면도 늘었고, Django와 Spring을 함께 운영하는 v3의 구성은 아직 마이그레이션 중인 과도기예요. v4 전면 전환을 어떻게 깔끔하게 마무리할지는 다음 시즌의 숙제로 남아 있습니다.
처음엔 수기로 받던 주문을 디지털로 옮기는 일이었는데, 결국 제가 손에 쥔 건 '동시에 들어오는 두 요청을 어떻게 어긋나지 않게 처리하느냐'였습니다. 그 뒤로 저는 어떤 기능을 짜든 가장 바쁜 순간을 먼저 떠올리는 사람이 됐고, 남은 v4 전환도 같은 태도로 마무리해 보려 합니다.