컷마다 LLM을 부르다 지친 이야기
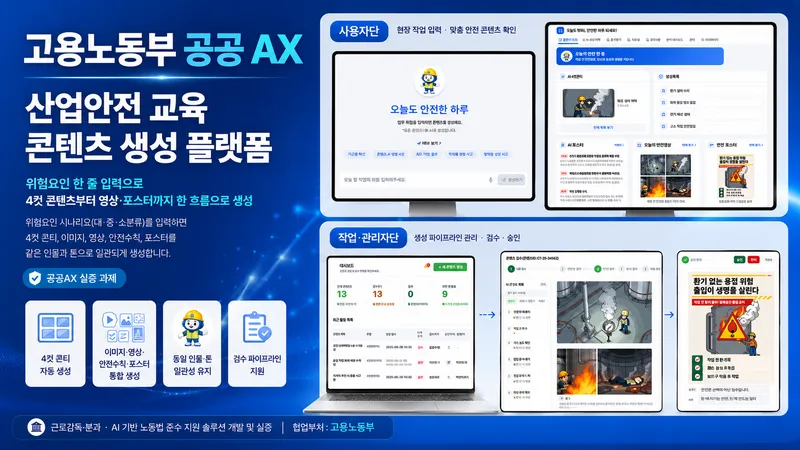
NEXV 인턴으로 AXProject 백엔드를 맡은 임현우입니다. AXProject는 고용노동부 근로감독 분과의 'AI 기반 노동법 준수 지원 솔루션 실증' 과제고(국정자원관리원 대구센터 GPU 서버에서 구동), 저는 그중 산업안전 교육 콘텐츠 생성 파이프라인을 맡았어요. 고위험사업장 예측이나 서류 위변조 탐지 같은 과제의 다른 솔루션은 제 범위가 아닙니다. 산업안전 교육 콘텐츠는 위험요인 하나만 다뤄도 콘티·이미지·영상·안전수칙·포스터를 전부 갖춰야 하는데요. 더 까다로운 건 이 다섯 가지가 같은 인물, 같은 톤으로 이어져야 한다는 점이었습니다.
컷이 네 개니까 컷마다 필요한 걸 그때그때 LLM에 물어보면 되겠지 — 그렇게 가볍게 시작했습니다. 그런데 막상 만들어 보니 호출이 한도 끝도 없이 쌓이기 시작했습니다. 1번 컷을 위해 부르고, 2번 컷을 위해 또 부르고, 안전수칙 뽑으려고 또 부르고요. 더 큰 문제는 그렇게 따로따로 부르다 보니 컷 사이의 등장인물과 맥락이 자꾸 어긋났다는 겁니다. 1번 컷에서 안전모 쓰고 점검하던 작업자가 3번 컷에서는 딴 사람이 되어 있는 식이었어요.
그러니까 이건 "LLM을 더 잘 부르는 법" 문제가 아니라, "애초에 몇 번을 부를 것인가"의 문제였습니다.
왜 한 줄 입력에서 끝까지 일관성이 어려웠을까요?
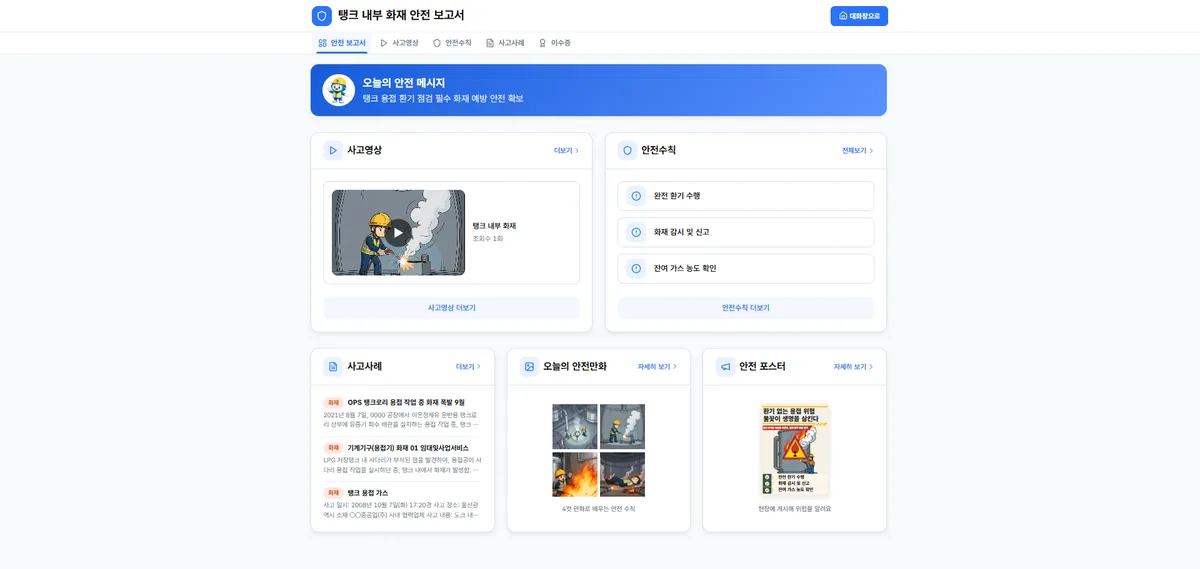
AXProject가 받는 입력은 사실 굉장히 간결합니다. 위험요인 시나리오를 대분류·중분류·소분류로 한 줄 넣으면 끝이거든요. 이를테면 "화학적 요인 — 탱크 내부 화재 — 용접 불티로 인한 화재" 같은 식입니다. 사용자가 바라는 출력은 이 한 줄에서 시작해 4컷 안전만화, 사고영상, 안전수칙, 포스터까지 한 흐름으로 나오는 것이고요.
문제는 입력은 한 줄인데 그 한 줄이 책임져야 할 출력이 너무 많았다는 점입니다. 콘티 4컷에, 각 컷의 이미지, 영상화할 장면, 캡션, 안전수칙, 포스터 문구까지요. 이걸 단계마다 LLM에게 "이번엔 이걸 만들어줘" 하고 따로 부탁하면, LLM은 매번 앞 컷에서 무슨 일이 있었는지 모르는 상태로 시작합니다. 사람으로 치면 회의 중간에 들어온 사람한테 자꾸 결정을 맡기는 셈이라, 맥락이 매번 새로 그려지는 거죠.
결국 호출이 늘수록 비용과 지연만 쌓이는 게 아니라, 컷 사이의 일관성이라는 핵심 품질이 깨지고 있었습니다. 컷마다 부르는 구조 그 자체가 문제였던 거예요.
그래서 어떻게 풀었나요?
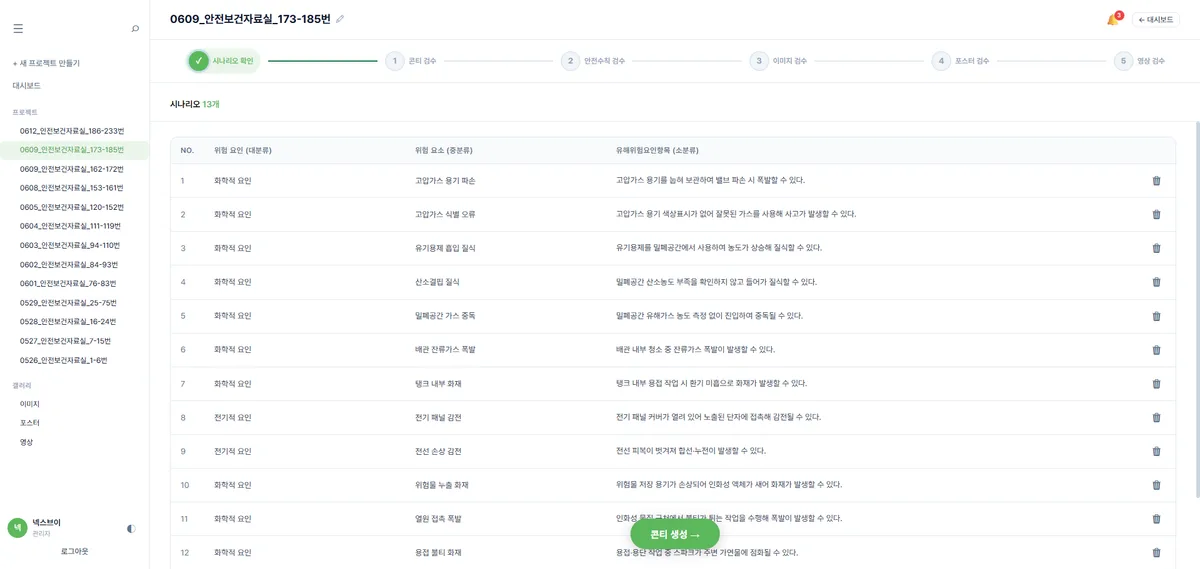
해결의 출발점은 하나였습니다. "4컷의 설계도를 먼저 한 번에 그려두고, 이후 단계는 그 설계도만 따라가게 하자." 컷마다 즉흥적으로 LLM을 부르는 대신, 시나리오를 받은 직후 '시나리오 분석'을 딱 한 번 수행해서 콘티 전체를 확정하는 방식이었습니다.
- 1
시도 1 — 컷별 호출
필요할 때마다 LLM을 부르는 직관적인 구조. 만들기는 쉬웠지만 호출이 누적됐고, 컷 사이 등장인물·맥락이 어긋났습니다.
- 2
한계
각 호출이 앞 컷의 맥락을 모른 채 시작하니, 캐릭터 일관성을 코드 후처리로 보장하기가 어려웠습니다.
- 3
시도 2 — 시나리오 분석 1회 통합
입력 직후 LLM을 한 번만 불러 4컷 콘티와 19개 슬롯을 동시에 산출. 이 결과를 4컷 전체의 설계도로 삼고, 이미지·영상·문서 생성이 그 설계도를 따라가게 했습니다.
- 4
결과
호출이 줄었고, 컷 사이의 맥락·연결이 하나의 분석 결과 안에서 보장됐습니다.
한 번의 분석으로 콘티 4컷과 19개 슬롯을 한꺼번에 뽑으니, 프롬프트 하나는 분명 무거워졌습니다. 하지만 그 대가로 컷 사이의 이야기가 한 결과 안에서 이어졌어요. 1번 점검 장면에서 시작해 2번 용접, 3번 화재, 4번 재해로 자연스럽게 흘러가는 식으로요. 트레이드오프를 표로 정리하면 이렇습니다.
| 결정 지점 | 컷별로 부르기 (AS-IS) | 시나리오 분석 1회 (TO-BE) |
|---|---|---|
| LLM 호출 | 컷·단계마다 누적 | 입력 직후 1회로 통합 |
| 콘티·슬롯 산출 | 단계마다 분산 | 4컷 콘티 + 19슬롯 동시 산출 |
| 컷 간 일관성 | 호출마다 맥락 단절 | 한 분석 결과 안에서 연결 |
| 프롬프트 부담 | 가볍지만 잦음 | 무겁지만 한 번 |
캐릭터가 컷마다 다른 사람이 되는 건 어떻게 막았나요?
콘티를 한 번에 확정해도, 이미지를 컷별로 생성하는 단계에서 또 한 번 일관성이 흔들릴 수 있었습니다. 같은 "안전모 쓴 작업자"라고 적어둬도, 이미지 모델은 컷마다 얼굴이며 복장이 미묘하게 다른 사람을 그려내거든요.
그래서 고정 캐릭터 시트를 기준점으로 삼았습니다. SAFETY HERO BOY라는 캐릭터를 정해두고, 컷별 이미지를 Qwen-Image-Edit로 이 시트를 기준 삼아 생성했어요. 새로 그리는 게 아니라 같은 인물을 변형해 나가는 방식이라, 컷이 바뀌어도 같은 작업자가 점검·용접·화재·재해를 차례로 겪는 한 편의 만화가 됐습니다.
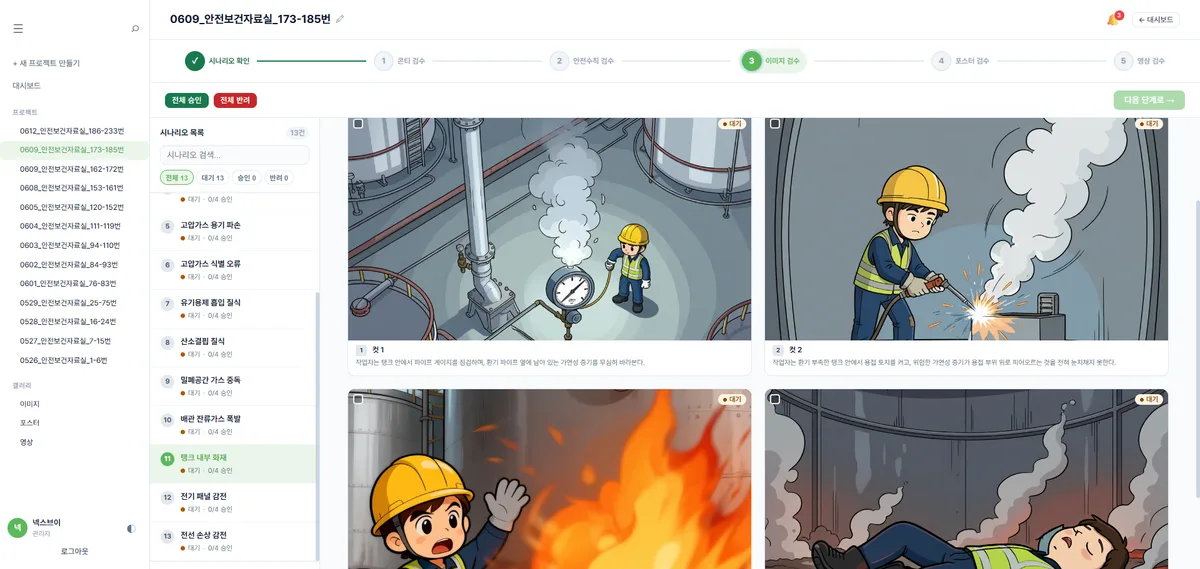
콘티는 한 번의 분석으로 묶고, 캐릭터는 시트로 고정한다. 일관성을 두 군데에서 따로 지키니 4컷이 비로소 "같은 이야기"로 읽혔습니다.
오래 걸리는 영상 생성은 어디에 두었나요?
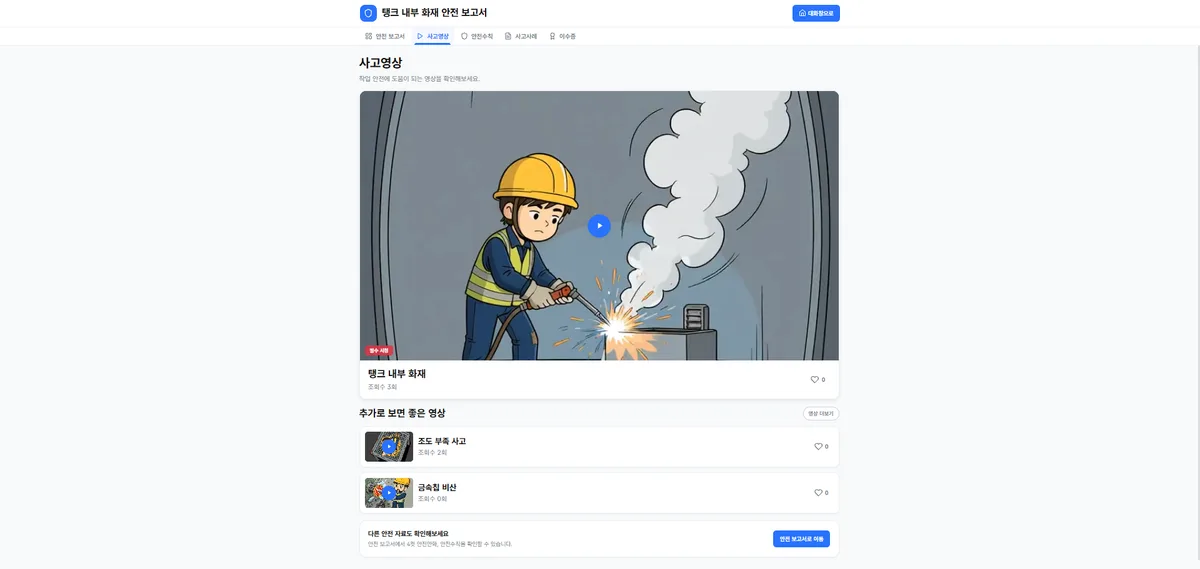
이미지까지는 비교적 빨리 나오는데, 영상은 사정이 달랐습니다. 사고영상은 컷2와 컷3을 Wan2.2 I2V로 각각 3초씩 생성한 뒤 ffmpeg xfade로 0.5초 디졸브를 줘서 한 편으로 합본하는데, 이 생성 자체가 시간이 꽤 걸렸습니다. 이걸 요청-응답 흐름 안에 그대로 두면 사용자가 화면 앞에서 하염없이 기다려야 했고요.
그래서 영상만큼은 동기 흐름에서 떼어냈습니다. 생성 요청을 받으면 잡으로 등록해 두고, video_dispatcher가 폴링으로 잡 큐를 돌면서 완성된 영상을 채워 넣는 비동기 구조로 만들었어요. 덕분에 사용자는 영상이 준비되는 동안 다른 산출물을 먼저 확인할 수 있게 됐습니다.
text# 영상은 동기 흐름에서 분리 — 잡 등록 후 dispatcher가 폴링 Wan2.2 I2V: 컷2(3s) + 컷3(3s) → ffmpeg xfade(0.5s) 합본 └ video_dispatcher 폴링 잡 큐로 비동기 처리
전체적으로 보면, 라우터에서 받아 서비스가 흐름을 조율하고 DAO가 데이터를 책임지는 레이어드 구조 위에 이 파이프라인을 올렸습니다. 시나리오 분석 1회가 4컷의 설계도가 되고, 이미지·영상·문서 생성이 그 설계도를 각자 따라가는 그림입니다.
프롬프트는 감으로 고치지 않았습니다
생성형 파이프라인에서 가장 흔들리기 쉬운 게 "이 프롬프트가 정말 더 나은가?"라는 판단이라고 봅니다. 보통은 결과를 한 번 보고 느낌상 괜찮으면 넘어가게 되는데요. 저는 여기서 검수를 데이터로 바꿔보려 했습니다.
생성된 이미지와 영상을 직접 검수하고, 배포 버전끼리 같은 시나리오로 산출물을 나란히 비교했습니다. 무엇이 더 효과적인지를 산출물 자체로 확인한 다음에야 프롬프트 템플릿을 손댔고, 개선한 템플릿은 V5로 정리해 마이그레이션 SQL로 반영했습니다. 사람이 검수하느라 손이 드는 건 분명한 비용이지만, 무엇이 통했는지를 추측이 아니라 산출물로 남길 수 있다는 점이 컸습니다.
| 검수 방식 | 감으로 고치기 | 산출물로 고치기 (채택) |
|---|---|---|
| 판단 근거 | 주관적 인상 | 배포 버전 간 산출물 비교 |
| 비용 | 낮음 | 검수에 사람 손이 듦 |
| 재현성 | 낮음 | 템플릿(V5) + 마이그레이션 SQL로 기록 |
그래서 무엇이 남았나요?
결과만 짧게 정리하면 이렇습니다. 컷마다 흩어지던 LLM 호출을 시나리오 분석 1회로 통합해, 한 번의 분석에서 4컷 콘티와 19개 슬롯을 동시에 산출하도록 만들었습니다. 캐릭터는 고정 시트로 일관성을 유지했고, 무거운 영상 생성은 잡 큐로 떼어냈습니다. 검수는 산출물 비교를 거쳐 프롬프트 템플릿 V5로 정리했고요.
배운 것과 남은 과제
이번 작업에서 가장 또렷하게 남은 건 "몇 번 부를 것인가"를 먼저 정하는 일이 "어떻게 잘 부를 것인가"보다 앞선다는 감각이었습니다. 일관성 문제를 호출 후처리로 막으려 했다면 끝없이 땜질했을 텐데, 분석을 한 번으로 모으니 일관성이 구조에서 따라왔거든요.
또 하나는 검수를 데이터로 다루는 습관입니다. 생성형 결과물도 추측이 아니라 배포 버전 간 비교로 검증하면 재현 가능한 개선이 된다는 걸, 프롬프트를 V5까지 고쳐오며 몸으로 익혔습니다.
남은 과제도 적어둡니다. 검수는 아직 사람 손에 기대는 부분이 큽니다. 어떤 산출물이 "더 낫다"를 사람이 비교해 판단하는 단계를 더 정량적인 기준으로 옮긴다면 검수 자체를 재현 가능하게 만들 수 있다고 봅니다. 시나리오 분석 1회로 4컷을 묶었듯, 검수도 더 자동화된 한 흐름으로 모으는 것을 제 다음 목표로 두고 있습니다.