들어가며 — "왜 이렇게 느려요?"라는 한 마디에서 시작했습니다
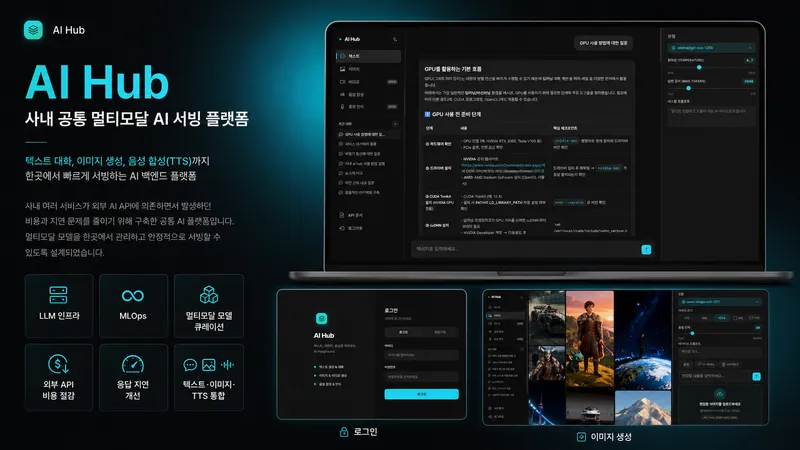
NEXV 인턴으로 사내 AI Hub의 LLM 인프라/MLOps와 멀티모달 모델 큐레이션을 맡았던 임현우입니다. AI Hub는 텍스트 대화, 이미지 생성, 음성 합성(TTS)을 한곳에서 받아 쓰는 사내 공통 AI 백엔드인데요. 제가 합류하고 가장 자주 들은 말이 "왜 이렇게 느려요?"였습니다.
사내 여러 서비스가 외부 AI API에 기대고 있었습니다. 호출이 늘수록 비용이 쌓였고, 응답은 좀처럼 빨라지지 않았어요. 그래서 저희 팀은 자체 호스팅으로 방향을 잡았는데, 막상 띄워 보니 이번엔 다른 벽이 있었습니다. 동시 요청 세 건만 들어와도 응답이 10초 넘게 밀리는 거였어요. 데모에서는 멀쩡하던 게, 사람 몇 명이 동시에 누르는 순간 한 줄로 줄을 서 버렸습니다.
느리다는 건 모두가 느꼈지만, 정작 "얼마나, 어디서" 느린지는 아무도 숫자로 말하지 못했습니다. 이 글은 그 "느리다는 감"을 측정 가능한 값으로 바꾸고, 병목을 찾아 추론 서버를 갈아 끼운 과정을 적은 기록입니다.
왜 이 문제가 어려웠을까요? — 비용과 지연이 같이 걸려 있었습니다
외부 API가 비싸면 직접 호스팅하고, 느리면 더 좋은 GPU를 붙이면 된다 — 처음엔 비용과 지연을 그렇게 따로 봤습니다. 그런데 막상 들여다보니 비용과 지연이 한 줄로 엮여 있었습니다. 둘 중 하나만 건드리면 다른 하나가 따라 나빠지는 구조였어요.
외부 API를 줄이려고 자체 모델을 띄우면 GPU 비용이 들어옵니다. 큰 모델일수록 품질은 좋지만 GPU를 더 먹고, 그러면 한 장에 여러 요청을 태워야 단가가 맞는데, 여러 요청을 동시에 태우면 이번엔 지연이 다시 올라갑니다. 텍스트뿐이라면 그나마 단순했을 텐데, 저희 허브는 이미지 생성과 음성 합성까지 같은 자원을 나눠 써야 하는 멀티모달이었습니다.
그래서 "무엇을 먼저 바꿔야 하는가"부터가 어려웠습니다. 추론 서버가 문제인지, 모델 크기가 문제인지, 컨텍스트로 들어가는 토큰이 문제인지 — 감으로는 셋 다 의심스러웠지만, 손은 하나뿐이니 순서를 정해야 했거든요.
느린 곳부터 찾자 — "감"을 동시처리량과 응답시간으로 바꿨습니다
그래서 가장 먼저 한 일은 모델을 바꾸는 게 아니라 재는 것이었습니다. 막연한 "느림" 대신 두 가지 값으로 문제를 다시 적었어요. 하나는 동시에 몇 건까지 받아낼 수 있는가(동시처리량), 다른 하나는 한 요청이 끝나기까지 얼마나 걸리는가(응답시간)였습니다.
재 보니 그림이 분명해졌습니다. 기존 Ollama 서빙은 요청이 들어오는 족족 거의 한 줄로 처리됐고, 그래서 동시 3건만 겹쳐도 뒤 요청이 앞 요청을 기다리느라 10초대로 밀렸습니다. 모델 자체가 느리다기보다, 동시에 들어온 요청을 함께 처리하지 못하는 게 병목이었어요. "느리다"의 정체는 모델 성능이 아니라 동시성 처리 방식에 있었습니다.
그래서 추론 서버를 vLLM으로 옮겼습니다 — 단점도 같이 받아들이며
병목이 동시성에 있다는 게 보이자, 해결의 방향도 정해졌습니다. 들어온 요청들을 한 줄로 세우지 말고 묶어서 함께 처리하는 추론 서버가 필요했어요. 저희 팀은 Ollama를 vLLM 자체 호스팅으로 교체하기로 했습니다.
물론 vLLM도 거저 얻은 건 아니었습니다. Ollama가 "한 줄로 띄우면 끝"에 가까웠다면, vLLM은 서빙 파라미터를 직접 잡고 GPU 위에서 운영해야 하는 만큼 운영 복잡도가 올라갑니다. 그래서 운영은 복잡해지지만 측정된 지연과 동시처리량이 확실히 좋아진다는 트레이드오프를 팀이 같이 확인하고 넘어갔어요. 단점을 덮지 않고 먼저 인정한 뒤 고른 결정이었습니다.
| AS-IS · Ollama | TO-BE · vLLM | |
|---|---|---|
| 동시 요청 처리 | 사실상 한 줄로 — 3건만 겹쳐도 밀림 | 묶어서 함께 처리 → 동시처리 약 4배 |
| 응답 시간 | 10초대 | 2~4초 |
| 운영 부담 | 낮음 (띄우면 끝) | 올라감 (서빙 파라미터·GPU 운영) |
bash# vLLM의 continuous batching — 요청을 한 건씩이 아니라 토큰 단위로 묶어 처리 vllm serve gpt-oss-120B \ --quantization int8 \ # 양자화로 GPU 메모리 절감 --tensor-parallel-size 2 # 120B 모델을 GPU 2장에 분산(가중치 분할)
비용은요? — 양자화와 컨텍스트 다이어트로 같이 잡았습니다
지연을 잡았으니, 처음의 다른 절반인 비용 차례였습니다. 큰 모델을 그대로 띄우면 GPU를 많이 먹는데, 사내 용도에서 매번 최상위 품질이 꼭 필요한 건 아니었어요. 그래서 대형 모델을 양자화해 GPU 비용을 낮췄습니다.
여기에도 트레이드오프가 있습니다. 양자화는 약간의 품질 손실을 동반하거든요. 다만 사내에서 쓰는 작업들에서는 그 손실이 체감되지 않는 선이었고, 줄어드는 GPU 비용이 훨씬 컸습니다. 약간의 품질을 내주고 비용을 크게 아끼는 균형을, 화려한 벤치마크가 아니라 실제 사내 용도에 맞춰 골랐어요.
비용은 GPU에만 있는 게 아니었습니다. 컨텍스트로 들어가는 토큰도 곧 돈이었어요. 그래서 RAG로 필요한 맥락만 추려 넣고, 긴 내용은 계층적 요약(2단계)으로 압축해 컨텍스트 토큰 자체를 줄였습니다. 모델에게 "다 읽어" 대신 "필요한 것만 읽어"를 시킨 셈입니다.
- 1
추론 서버 교체
Ollama 병목 → vLLM 자체 호스팅으로 동시처리량을 끌어올림
- 2
모델 양자화
대형 모델 양자화로 GPU 비용 절감 (사내 용도에 맞춘 품질-비용 균형)
- 3
컨텍스트 다이어트
RAG + 계층적 요약(2단계)으로 토큰 비용 관리
텍스트만으로는 부족했습니다 — 이미지·음성까지 한 허브로
사내에서 필요로 한 건 채팅만이 아니었습니다. 어떤 서비스는 이미지를 만들어야 했고, 어떤 서비스는 음성이 필요했어요. 이걸 서비스마다 따로 붙이면 다시 외부 API와 비용·관리 부담이 흩어집니다. 그래서 저희 팀은 텍스트·이미지·음성을 한 플랫폼에서 서빙하는 멀티모달 허브로 묶었습니다.
텍스트는 gpt-oss-120B, 이미지는 qwen-image, 음성은 MeloTTS를 자체 호스팅으로 올렸습니다. 저는 이 과정에서 모델을 다운로드하고, 튜닝하고, 어떤 작업엔 어떤 모델이 맞는지 골라내는 큐레이션 라이프사이클을 맡았어요. 모델 하나를 띄우는 것보다, 이 용도엔 이 모델 저 용도엔 저 모델을 정리해 두는 일이 실제로는 더 손이 갔습니다.

결과적으로 사내 서비스들이 외부 API를 각자 부르는 대신, 공통 허브 하나로 텍스트·이미지·음성을 모두 받아 가는 그림이 됐습니다.
그래서 무엇이 달라졌나요?
감으로 말하던 "느림"을 숫자로 바꾸고 병목부터 손대니, 결과도 같은 단위로 말할 수 있게 됐습니다.
| 지표 | 값 |
|---|---|
| 추론 처리량 | 약 4배 (동시처리 기준) |
| 응답 시간 | 10초대 → 2~4초 |
| 허브 연동 | 사내 서비스 3곳 이상이 공통 AI 백엔드로 사용 |
외부 API에 흩어져 있던 비용·지연을 한 허브로 모아, 텍스트·이미지·음성을 더 싸고 빠르게 서빙하게 됐다는 게 가장 큰 변화였습니다.
배운 것과 남은 과제 — 인프라에선 직관보다 데이터였습니다
가장 크게 남은 건 "재고 나서야 보였다"는 경험이었습니다. "느리다"를 감으로 두었을 때는 더 큰 GPU나 더 좋은 모델을 떠올렸지만, 동시처리량과 응답시간으로 다시 적자 진짜 병목은 추론 서버의 동시성 처리 방식이었어요. 인프라에서 직관보다 데이터로 판단한다는 게 어떤 의미인지, 이 프로젝트에서 처음으로 손에 잡혔습니다.
물론 끝난 이야기는 아닙니다. 양자화로 내준 품질을 어디까지 허용할지, 멀티모달 모델들이 같은 GPU 자원을 두고 경합할 때 어떻게 나눌지, 큐레이션한 모델 선택이 시간이 지나도 여전히 최선인지 — 재고 다시 정해야 할 질문들이 남아 있습니다.
저는 이 일을 거치며 느리다는 감을 숫자로 바꾸고 병목부터 손대는 순서를 제 일하는 방식으로 익혔습니다. 다음 병목을 만나도 먼저 재고 그다음 바꾸는, 그 태도를 계속 들고 가려 합니다.